The heart of the machine is original
Author: Zhu Zihao
Editor: Haojin Yang
Neural network pruning technology can greatly reduce network parameters, reduce storage requirements, and improve the computational performance of reasoning. And at present, the best methods in this field can usually maintain high accuracy. Therefore, the research on sparse architecture generated by pruning is a very important direction. The idea of this topic is to make an in-depth interpretation of the following two papers and explore the best pruning methods today.
Deep neural networks have achieved great success in the field of computer vision, such as AlexNet and VGG. These models have hundreds of millions of parameters at every turn. Traditional CPU can’t do anything about such a huge network, and only GPU with high computing power can train neural networks relatively quickly. For example, AlexNet model, which won the championship in ImageNet competition in 2012, used a 60-million-parameter network with five convolution layers and three fully connected layers. Even if the top K40 at that time was used to train the whole model, it would still take two to three days. The appearance of convolution layer solves the problem of parameter scale of fully connected layer, but after several convolution layers are superimposed, the training overhead of the model is still very large.
Now that there is a more powerful GPU, it is not a problem to calculate a deeper neural network with more parameters. But in fact, not everyone has several cards. For neural networks with more layers and nodes, it is very important to reduce their storage and calculation costs. Moreover, with the popularity of mobile devices and wearable devices, how to make these models well applied in mobile terminals with weak computing power has become an urgent problem. Therefore, more and more researchers began to study neural network model compression.
Synthesizing the existing model compression methods, they are mainly divided into four categories: parameter pruning and sharing, low-rank factorization, transferred/compact convolutional filters, and knowledge distillation [1].
This paper mainly interprets two papers on neural network pruning. The first paper, "The Lotteries Ticket Hypothesis: Finding Sparse, Trainable Neural Networks", was published on ICLR’19 by MIT team. The lottery hypothesis is put forward: the dense and randomly initialized feedforward network contains sub-networks ("winning lottery tickets"), and when trained independently, these sub-networks can achieve the same test accuracy as the original network in similar iterations. This paper won the best paper award. The second article "De Construction Lotteries Tickets: Zeros, Signs, and the Super Mask" is a deep deconstruction of the lottery hypothesis by Uber AI team.
Paper 1: The Lotterity Ticket Hypothesis: Finding Sparse, Trainable Neural Networks

Original link: https://arxiv.org/abs/1803.03635
introduce
Training machine learning model is one of the most expensive aspects in data science. For decades, researchers have proposed hundreds of methods to improve the training process of machine learning model, which are based on an axiomatic assumption that training should cover the whole model. Recently, researchers from MIT published a paper to challenge this hypothesis, and put forward a simpler method to train neural networks by paying attention to sub-networks. MIT researchers gave an easy-to-remember name-"Lottery Ticker Hypothesis".
The training process of machine learning is one of the compromises that data scientists face between theory and reality. Usually, due to the limitation of training cost, the ideal neural network architecture can not be fully realized for specific problems. Generally speaking, the initial training of neural network needs a large number of data sets and expensive calculation cost, and as a result, a huge neural network structure full of complex connections between hidden layers is obtained. This structure often needs to be optimized by removing some connections to adjust the size of the model. A question that has puzzled researchers for decades is whether we really need such a huge neural network structure. Obviously, if we connect every neuron in the network, we can solve a specific problem, but we may be forced to stop because of the high cost. Can’t we start with a smaller and leaner network? This is the essence of the lottery hypothesis.
Taking gambling as an analogy, training the machine learning model is equivalent to obtaining the winning lottery ticket by buying every possible lottery ticket. But if we know what the winning lottery looks like, can we choose the lottery more intelligently? In the machine learning model, the huge neural network structure obtained in the training process is equivalent to a big bag of lottery tickets. After the initial training, the model needs to be optimized, such as pruning and deleting unnecessary weights in the network, thus reducing the size of the model without sacrificing performance. This is equivalent to finding the winning lottery ticket in the bag and then throwing away the remaining lottery tickets. Usually, the network structure after pruning is about 90% smaller than the original one. Then the question is, if the network structure can be reduced, why not train this smaller network from the beginning in order to improve the training efficiency? However, many experiments have proved that if the pruned network is trained from scratch, the accuracy is much lower than that of the original network.
The idea behind MIT’s lottery hypothesis is that a large neural network contains a small sub-network, and if it is trained from the beginning, it will get similar accuracy to the original network.
Lottery hypothesis
The formal definition of the lottery hypothesis in this paper is that a randomly initialized dense neural network contains an initialized sub-network, which can achieve the same test accuracy as the original network after the same number of iterations at most when training alone.
We regard all the parameters of a complex network as the prize pool, and the subnet corresponding to the above set of sub-parameters is the winning lottery.
More formally, consider a dense feedforward neural network f(x; θ), where the initialization parameter θ=θ_0~D_θ. When descending with random gradient on the training set, F can achieve loss L and accuracy A after J iterations. In addition, consider applying a 01 mask m ∈ {0,1 }| θ| to the parameter θ, and train f(x; M⊙θ), f reaches loss L’ and accuracy A’ after j’ iterations. The lottery hypothesis indicates the existence of m, which makes j < = j (faster training time), a > = a (higher accuracy), ||| m || _ 0 < | θ| (fewer parameters).
How to find the winning lottery ticket
If the lottery hypothesis is correct, then the next question is how to design a strategy to find the winning lottery. The author puts forward a method to find the winning lottery ticket by iteration:
1. Randomly initialize a complex neural network.
2. train this network j times until it converges.
3. Cut off some weight parameters
4. Initialize the remaining sub-networks with the weights in step 1 to create winning lottery tickets.
5. In order to evaluate whether the sub-network obtained in step 4 is a winning lottery ticket, train the sub-network and compare the accuracy.
The above process can be carried out once or many times. When there is only one pruning, the network is trained once, and the weight of p% is cut off. In this paper, pruning is carried out N times iteratively, and the weight of P (1/n)% is cut off each time.

experimental analysis
The author has done a lot of experiments on the fully connected neural network for MNIST and the convolutional neural network for CIFAR10 respectively. Take MNIST experiment as an example here:

Pm represents how many parameters are left in the network. It can be observed from Figure 3 that the performance of sub-networks with different pruning rates is different. When Pm>21.2%, the smaller the Pm, that is, the more pruning parameters, the higher the accuracy. When Pm<21.1%, the smaller the Pm, the lower the accuracy. The winning lottery ticket converges faster than the original network, and has higher accuracy and generalization ability.

It can be observed from Figure 4 that iterative pruning can find the winning lottery ticket faster than oneshot pruning, and it can still achieve high accuracy in the case of small sub-network. In order to measure the importance of initialization in winning lottery tickets, the author keeps the structure of winning lottery tickets and then uses random initialization to retrain. Different from the winning lottery, the re-initialized network learning speed is slower than the original network, and the test accuracy will be lost after a small amount of pruning.
summary
In this paper, the author puts forward the lottery hypothesis and gives a method to find the winning lottery ticket. A subnet can be found by iterative unstructured pruning, and it can be trained faster with the initialization parameters of the original network, but the same performance can not be achieved if the random initialization method is used.
The author also points out some problems in this work. For example, the calculation of iterative pruning is too large, and a network needs to be trained for 15 or more times in a row. In the future, we can explore more efficient ways to find winning lottery tickets.
Paper 2: de construction lotty tickets: Zeros, signs, and the super mask.

Original link: https://arxiv.org/abs/1905.01067
Review of lottery hypothesis
Frankle and Carbin put forward a model pruning method in the lottery hypothesis (LT) paper: after training the network, reset all the weights less than a certain threshold to 0 (pruning), then reset the remaining weights to the initial weights of the original network, and finally retrain the network. Based on this method, two interesting results are obtained.
On the one hand, the performance of a heavily pruned network (with 85%-95% weight removed) has not obviously decreased compared with the original network, and if only 50%-90% weight is removed, the network performance will often be higher than the original network. On the other hand, for the trained ordinary network, if the weights are re-randomly initialized and then trained, the results are equivalent to those before. However, the network with lottery hypothesis does not have this feature. Only when the network uses the same initialization weight as the original network can it be well trained, and if it is reinitialized, the result will be worse. The specific combination of pruning mask (if the deletion right is reset to 0, otherwise it is 1) and weight constitutes the winning lottery ticket.
existing problems
Although the lottery hypothesis is proved to be effective in the last paper, many potential mechanisms have not been well understood. For example, how does LT network make them show better performance? Why is the mask and the initial weight set so tightly coupled that reinitializing the network will reduce its trainability? Why simply choosing a large weight constitutes an effective criterion for selecting a mask? Will other criteria for selecting masks also work? This paper puts forward the explanation of these mechanisms, reveals the special modes of these sub-networks, introduces a variant that competes with the lottery algorithm, and obtains an unexpected derivative: supermask.
Mask criterion
The author sets the mask value of each weight as the function M(w_i,w_f) of the initial weight and the trained weight, which can be visualized as a set of decision boundaries in two-dimensional space, as shown in Figure 1. Different masking standards can be considered as dividing a two-dimensional (wi = initial weight, wf = final weight) space into regions with a mask value of 1 vs 0.

As shown in the figure, the masking criterion is identified by two horizontal lines, which divide the whole area into mask =1 (blue) area and mask =0 (gray) area, corresponding to the masking criterion used in the last paper: keep the final large weight and cut off the weight close to zero. The author calls this large _ final mask, m (w _ i, w _ f) = | w _ f |. The author also put forward eight other mask criteria, and the corresponding formulas are shown in the figure below, which keep the weight of the colored part of the ellipse and cut off the weight of the gray part.

The author has done a series of comparative experiments on these mask criteria, and the results for fully connected and Conv4 networks are shown in the following figure. It can be found that magnitude increase is comparable to large_final, and it will perform better in Conv4 network.

Taking the random mask as the baseline, we can find that those criteria that tend to retain the weight with a large final value can better find the subnet, but the effect of retaining the small weight is poor.
Importance of sign
Now we have explored which weights are better for impairment. The next question is how to reset the remaining weights. The author mainly wants to study an interesting result in the last paper. It works well when it is reset to the initial value of the original network, but it will get worse when it is initialized randomly. Why does reinitialization get worse and what are the most important initialization conditions? In order to find the answer to the question, the author has done a series of initialization experiments.
Reinit: Initialize the reserved weights based on the original initialization distribution.
Refresh: Initialize based on the original distribution of reserved weights.
Constant: Set the reserved weight to a positive or negative constant, that is, the standard deviation of the original initial value of each layer.
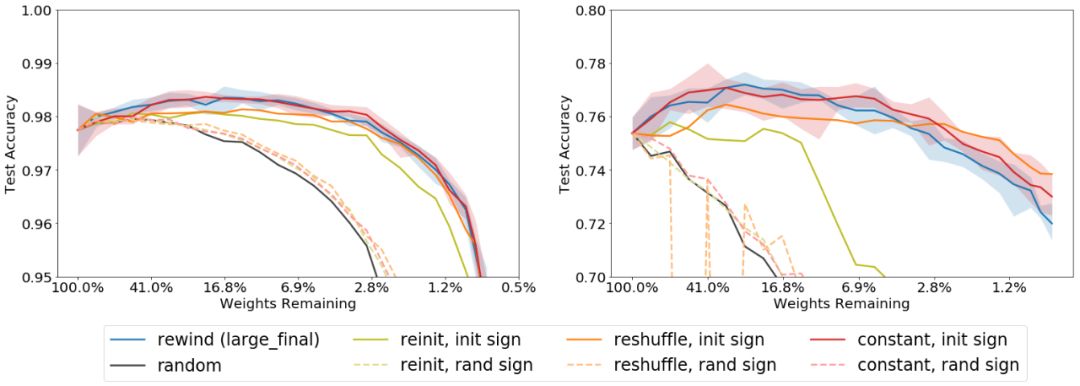
It can be found that preserving the initial value of the weight is not as important as preserving the sign. If other initialization methods are used, but the sign is ignored, the effect is very poor, which is similar to random initialization (dotted line in the figure). However, if the original weights keep the same sign, the initialization effect of the three methods is almost the same as that of LT network (solid line in the figure). As long as the signs are consistent, even if the remaining weights are set to be constant, it will not affect the performance of the network.
Supermask
At the beginning, the concept of super mask is mentioned, which is a binary mask. When it is used in randomly initialized networks, it can get higher accuracy even without retraining. Here’s how to find the best super mask.
Based on the above insight into the importance of the initial symbol and the consideration of making the weights closer to the final value, the author introduces a new mask criterion, selects larger weights, and these weights also keep the same sign after training, which the author calls large_final, same sign. And use large _ final and diffsign as control, and the difference between them is shown in the following figure.

By using this mask criterion, 80% of the test accuracy can be achieved on MNIST, while the accuracy of the large_final method in the last article is only 30% at the best pruning rate (note that this is without retraining).

summary
This article gives an in-depth explanation of the last article. By comparing different mask criteria and initialization schemes, we can answer why the lottery hypothesis can perform well. And interestingly, a new "super mask" is proposed, through which high accuracy can be obtained without retraining the subnet. This provides us with a new neural network compression method, which can reconstruct the weight of the network only by saving the mask and random number seeds.
references
1. Cheng, Yu, et al. "A survey of model compression and acceleration for deep neural networks." arXiv preprint arXiv:1710.09282 (2017).
2. Frankle, Jonathan, and Michael Carbin. "The lottery ticket hypothesis: Finding sparse, trainable neural networks." ICLR (2019).
3. Zhou, Hattie, et al. "Deconstructing lottery tickets: Zeros, signs, and the supermask." arXiv preprint arXiv:1905.01067(2019).
4. https://eng.uber.com/deconstructing-lottery-tickets/
5. https://towardsdatascience.com/how-the-lottery-ticket-hypothesis-is-challenging-everything-we-knew-about-training-neural-networks-e56da4b0da27
Author introduction: Zhu Zihao, currently a graduate student of Institute of Information Engineering, Chinese Academy of Sciences, whose main research interests are graph neural network, multimodal machine learning, visual dialogue and so on. I like scientific research and sharing. I hope to learn and communicate with you through the heart of the machine.
This article is original for the heart of the machine, please contact Ben WeChat official account for authorization.
✄————————————————
Join the heart of the machine (full-time reporter/intern): hr@jiqizhixin.com
Contribute or seek reports: content@jiqizhixin.com.
Read the original text